tl;dr: use the direct reply-to feature to implement RPC in RabbitMQ.
I’m currently working on a platform that relies heavily on RPC over RabbitMQ to move incoming requests through a chain of Node.JS worker processes. The high level setup for RPC is well described in RabbitMQ’s documentation; let’s steal their diagram:
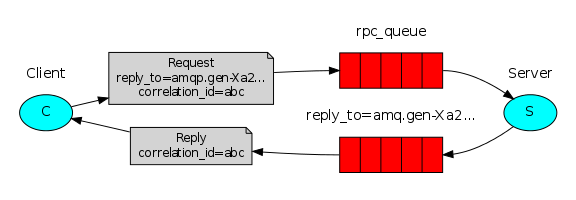
We grew our RPC client code based on the JavaScript tutorial, using the amqp.node module. The first —admittedly naive— implementation just created a new connection, channel and queue per request and killed the connection after getting a reply:
const sendRPCMessage = (settings, message, rpcQueue) =>
amqp.connect(settings.url, settings.socketOptions)
.then((conn) => conn.createChannel())
.then((channel) => channel.assertQueue('', settings.queueOptions)
.then((replyQueue) => new Promise((resolve, reject) => {
const correlationId = uuid.v4();
const msgProperties = {
correlationId,
replyTo: replyQueue.queue
};
function consumeAndReply (msg) {
if (!msg) return reject(Error.create('consumer cancelled by rabbitmq'));
if (msg.properties.correlationId === correlationId) {
resolve(msg.content);
}
}
channel.consume(replyQueue.queue, consumeAndReply, {noAck: true})
.then(() => channel.sendToQueue(rpcQueue, new Buffer(message), msgProperties));
})));
That got us a long way during development but obviously failed to perform under non-trivial loads. What was more shocking is that it got dramatically worse when running it on a RabbitMQ cluster.
So we needed to refactor our client code. The problem is that most examples show how to send one-off RPC messages, but aren’t that clear on how the approach would be used at scale on a long-lived process. We obviously needed to reuse the connection but how about the channel? Should I create a new callback queue per incoming request or a single one per client?
Using a single reply-to queue per client
Based on the tutorial, I understood that the sensible approach was to reuse the queue from which the client consumed the RPC replies:
In the method presented above we suggest creating a callback queue for every RPC request. That’s pretty inefficient, but fortunately there is a better way – let’s create a single callback queue per client. That raises a new issue, having received a response in that queue it’s not clear to which request the response belongs. That’s when the correlation_id property is used.
We were already checking the correlationId, and just needed to create the reply-to queue in advance:
const createClient = (settings) =>
amqp.connect(settings.url, settings.socketOptions)
.then((conn) => conn.createChannel())
.then((channel) => channel.assertQueue('', settings.queueOptions)
.then((replyQueue) => {
channel.replyQueue = replyQueue.queue;
return channel;
}));
I thought that would be enough to make sure the right consumer got the right message, but in practice I found that each message was always delivered to the first consumer. Therefore, I needed to cancel the consumer after the reply was processed:
const sendRPCMessage = (channel, message, rpcQueue) =>
new Promise((resolve, reject) => {
const correlationId = uuid.v4();
const msgProperties = {
correlationId,
replyTo: channel.replyQueue
};
function consumeAndReply (msg) {
if (!msg) return reject(Error.create('consumer cancelled by rabbitmq'));
if (msg.properties.correlationId === correlationId) {
channel.cancel(correlationId)
.then(() => resolve(resolve(msg.content)));
}
}
channel.consume(channel.replyQueue, consumeAndReply, {
noAck: true,
// use the correlationId as a consumerTag to cancel the consumer later
consumerTag: correlationId
})
.then(() => channel.sendToQueue(rpcQueue, new Buffer(message), msgProperties));
});
Enough? Only if the client processed one request at a time. As soon as I added some concurrency I saw that some of the messages were not handled at all. They were picked up by the wrong consumer, which ignored them because of the correlationId check, so they were lost. I needed to do something about unexpected message handling.
Requeuing unexpected messages
I tried using nack when a consumer received a reply to a message with an unexpected correlationId:
function consumeAndReply (msg) {
if (!msg) return reject(Error.create('consumer cancelled by rabbitmq'));
if (msg.properties.correlationId === correlationId) {
channel.ack(msg);
channel.cancel(correlationId)
.then(() => resolve(resolve(msg.content)));
} else {
channel.nack(msg);
}
}
Now the messages seemed to be handled, eventually. Only they weren’t: when I increased the load I saw message loss again. Further inspection revealed that the consumers were entering a weird infinite loop:
Consumer A gets message B; message B requeued Consumer B gets message C; Message C requeued Consumer C gets message A; Message A requeued
Repeated ad-infinitum. The same behaviour was reproduced using every possible combination of nack, reject and sendToQueue to send back the message.
Googling the issue, I read about the possibility of using Dead letter exchanges to handle those cases. But having to manually requeue unexpected messages felt weird enough; introducing a new exchange and queue sounded like a lot of effort to handle what should be a pretty standard use case for RPC. Better to take a step back.
Using a new reply-to queue per request
So I went back to a reply-to queue per request. This was marginally better than our initial approach since now at least we were recycling the connection and the channel. What’s more, that appeared to be the standard way to do RPC in RabbitMQ according to the few spots where I found non-tutorial implementation details, so, as Paul Graham would say, we wouldn’t get in trouble for using it.
And it worked well for us as long as we run a single RabbitMQ instance. When we moved to a RabbitMQ cluster the performance was pretty much the same as when we were creating connections like there was no tomorrow.
Using direct reply-to
We were seriously considering dropping the RabbitMQ cluster altogether (which meant turning our broker into a single point of failure), when I came across the link to the direct reply-to documentation. The first interesting thing there was that it confirmed why we were seeing such bad performance when running a RabbitMQ cluster:
The client can declare a single-use queue for each request-response pair. But this is inefficient; even a transient unmirrored queue can be expensive to create and then delete (compared with the cost of sending a message). This is especially true in a cluster as all cluster nodes need to agree that the queue has been created, even if it is unmirrored.
Direct reply-to uses a pseudo-queue instead, avoiding the queue declaration cost. And fortunately it was fairly straightforward to implement:
const createClient = (settings) => amqp.connect(settings.url, settings.socketOptions)
const sendRPCMessage = (client, message, rpcQueue) => conn.createChannel()
.then((channel) => new Promise((resolve, reject) => {
const replyToQueue = 'amq.rabbitmq.reply-to';
const timeout = setTimeout(() => channel.close(), 10000);
const correlationId = uuid.v4();
const msgProperties = {
correlationId,
replyTo: replyToQueue
};
function consumeAndReply (msg) {
if (!msg) return reject(Error.create('consumer cancelled by rabbitmq'));
if (msg.properties.correlationId === correlationId) {
resolve(msg.content);
clearTimeout(timeout);
channel.close();
}
}
channel.consume(replyToQueue, consumeAndReply, {noAck: true})
.then(() => channel.sendToQueue(rpcQueue, new Buffer(content), msgProperties))
});
This worked just as we expected, even in the cluster. As the code shows, though, we were still creating a new channel per request and we needed to handle its closing, even when the response never came. Trying to use a single channel resulted in a “reply consumer already set” error, because the queue was always the same.
Creating so many channels didn’t feel right, so I filed an issue asking for advice in the amqp.node repo. The creator confirmed that that was indeed an anti-pattern and suggested not only using a single channel but registering a single consumer (i.e. a single callback function to handle all RPC responses). This meant introducing some structure to be able to route responses back to the promise that was expecting it. Using an EventEmitter turned out to be an elegant way to accomplish it:
const REPLY_QUEUE = 'amq.rabbitmq.reply-to';
const createClient = (settings) => amqp.connect(settings.url, settings.socketOptions)
.then((conn) => conn.createChannel())
.then((channel) => {
// create an event emitter where rpc responses will be published by correlationId
channel.responseEmitter = new EventEmitter();
channel.responseEmitter.setMaxListeners(0);
channel.consume(REPLY_QUEUE,
(msg) => channel.responseEmitter.emit(msg.properties.correlationId, msg.content),
{noAck: true});
return channel;
});
const sendRPCMessage = (channel, message, rpcQueue) => new Promise((resolve) => {
const correlationId = uuid.v4();
// listen for the content emitted on the correlationId event
channel.responseEmitter.once(correlationId, resolve);
channel.sendToQueue(rpcQueue, new Buffer(message), { correlationId, replyTo: REPLY_QUEUE })
});

Good read
Great work ! Do you have any examples with some snipets ? thx !
The snippets I have are pretty much those you see in the post (and in the amqp.node issue I linked).
How do we call this function?
What function?
mine was typescript
public async postSurvey(survey: Survey): Promise {
createClient(settings).then((channel) => {
sendRPCMessage(channel, survey, “survey_q_req”).then((data) => {
return data;
});
})
}
this cannot be compiled it’s complaining
[ts] A function whose declared type is neither ‘void’ nor ‘any’ must return a value.
Thanks for the write-up. Was wondering; does this work in a Node.js cluster? E.g. if I use a cluster module in my Node.js server, will the EventEmitter stuff still communicate properly? Thanks.
Also, what if you have multiple instances of this server running?
Assuming each worker has its own connection there won’t be a problem. The direct reply-to queue knows how to match the reply to the proper connection and channel. Then the EventEmitter bit (which could also just be a map), matches it to the proper consumer within that channel.
I’ve used this setup with multiple server instances and with PM2 in cluster mode and it worked well.
Thanks for the reply, glad to hear you haven’t had issues with it.
I guess I’ll need to run a test for this, but I’m curious if you run 2 processes (a master and a worker), and this happens:
1. you call sendRPCMessage twice (one call happens to be in master process with correlationId of say, “1-2-3”, and second call is in the worker with a correlationId of “4-5-6”)
2. the second call with correlationId “4-5-6” completes first, and the master process consumer picks up the reply to “4-5-6” and emits an event with that correlationId, but there’s no listener for that correlationId in the master process, so it drops it silently.
Essentially it ends up looking like one of the first problems you mentioned (but just in a slightly different set up):
> They were picked up by the wrong consumer, which ignored them because of the correlationId check, so they were lost.
But if you have two processes then each one of them would have a different connection/channel to rabbit, right (i.e. they will be different consumers)? So only the consumer that sends the request will receive the response for that message. The correlationId is to differentiate responses inside a given consumer.
Ah yes that’s what I was missing. One channel per worker solves it. Thanks for clarifying. Saved my day.
Hello,
I am trying to implement this and i get the following error:
Error: Channel closed by server: 404 (NOT-FOUND) with message “NOT_FOUND – no queue ‘amq.rabbitmq.reply-to’ in vhost ‘/'”
I am using CreateClient as is, but i can’t initiate the application.
Thanks in advance
Mmm I can’t really tell, you’ll have to google it. Make sure there isn’t a typo in the queue name and that your rabbit version support this feature
I found the problem.
I have that error because I was using RabbitMQ version 3.3.5 .
I upgraded the RabbitMQ to the most recent version (3.6.10) and it works very good.
Thanks for the great article.
Hi,
I’ve implemented your code, creating a wrapper to amqplib, and I have two questions:
1. The channels keep stacking up, eventually in high load, RabbitMQ has no more memory
2. How to handle reconnection?
Regards
1. Why do channels stack up? You should be using a single channel per client as exaplained at the end.
2. Reconnection is not a trivial issue, and I haven’t solved it in node.js, you should take a look at the github issues of ampq.node and possibly checking what other clients do.
I am chaining multiple RPC clients / servers connections for each request to the API, depending on settings, therefore a single app can be server and client at the same time, but in different moments. It handles correctly all replys, but then I have connections that can stack up thousands of channels. If there was any way, I would share with you a gist with the code I’m handling with
It’s hard to tell without knowing your use case, but if you have 1k channels I imagine you are somehow recreating your channels on each request? If your app can be both server and client then you could have a server channel and a client channel, or if you have different types of servers and clients, then a channel per each of those, but reusing them across requests.
Hello,
very nice post ! I’m trying to do the same but in your last exemple, how do you handle timeout for the client ? Do you send a message without expire ? It’s not a problem to have many listener for the same EventEmmiter instance ?
Thanks
The code samples were kept simple for this article purposes, but yes, depending on your situation you may want to add timeouts and remove stale listeners.
And it’s not a problem to have many listener for the same EventEmmiter instance ?
Not really, as long as you remove them after the reply comes in (in my example I use `once` to accomplish that). By default Node will show a warning if you have more than 10 at a time, but you can change this (that’s what the setMaxListeners call does).
Alternatively you could just have a Map or Object that maps correlationId to consumer function.
Pingback: Building a simple service relay for Dynamics 365 CE with RabbitMQ and Python - part 4 - Microsoft Dynamics CRM Community
Hi there, I am very new to RabbitMQ, so it is all a little complex for me just jet. Your solution sounds exactly what I need.
I’m trying to create the client like so:
`createClient({ url: ‘amqp://172.17.0.1’, socketOptions: {} })`
However I am getting an error when I try to start the app:
“`
.then((conn) => conn.createChannel())
^
TypeError: Cannot read property ‘then’ of undefined
“`
I would appreciate some guidance please, that am I doing wrong?
I’ve defined amqp as in the tutorial: let amqp = require(‘amqplib/callback_api’)
Other than that, I did not change anything.
Sorry about that, I have figured out that I should not use “/callback_api” when I work with promises ‘:D
When I passed through that part, I got error that EventEmitter is not defined so I had this workaround:
let events = require(‘events’)
// rest of the code…
channel.responseEmitter = new events.EventEmitter();
It seems okay until I try to send a message:
sendRPCMessage(createClient({url: ‘amqp://172.17.0.1’, socketOptions: {}}), ‘test’, ‘queue_name’)
I get an error:
TypeError: Cannot read property ‘once’ of undefined
Do you have a different EventEmitter? How is that you did not need to define it like I did?