This month I published an article about profiling in Erlang at NextRoll’s Tech Blog.
Category Archives: Uncategorized
Rust, Open-Source and dogs
Some years ago I learned a programming language that made a profound impact in the way I think about software; a language that I enjoyed working with, that enabled me to meet some amazing people and pushed me to get more involved in Open-Source and community than I ever did before. I stopped using it because it couldn’t get me the job I wanted, and I needed to switch my efforts to mastering the tools that could. I later became disenchanted with that language and its ecosystem because of how it is managed; because the interests of the greater community of its users seemed to be secondary —sometimes even opposed— to the needs of the company that owns it.
I made multiple attempts at writing a blog post explaining why I lost interest in that language; a little out of frustration, a little because if had known better I wouldn’t have invested so much time in it. But I could never shape the text in a way that couldn’t be perceived as a rant or an attack and so I left it unfinished, popping up from the back of my head every now and then.
A couple of months ago me and my girlfriend got a dog. She insisted that we got one ever since we moved together and I kept putting it off because I wasn’t a dog person and I didn’t want to be responsible for another living being, not just yet. Eventually, I gave in. One of the things that she first showed me when Cumbia (my dog) got home was that to teach her how I wanted her to behave I shouldn’t focus on punishing mistakes but rather on rewarding accomplishments. This required (and still requires) an effort from my part; pessimistic as I am, I tend to put more attention to the negative side of things.

The servo logo is an instance of Rust+dogs which I include here to make the title sound less arbitrary
The past weekend I took the ferry across the Río de la Plata to Montevideo to assist to the Rust Latam conference, along with The Boss and other LambdaClass coworkers. As the talks progressed —following a first day where I took a great game development workshop—, I kept getting this feeling that this is the kind of Open-Source software community I want to invest myself in. Yes, the people that know better and have put the biggest effort are the ones calling the shots, but the discussions are open and anyone can weigh in. What’s more, small contributions, beginner contributions are not only welcome but necessary because that’s how the project grows and the language evolves to become a better tool, one increasingly helpful for an increasing amount of people.
It became apparent to me that the best way to scratch the itch of my previous Open-Source disappointment was to focus on the accomplishments of this community rather than clinging on what I disliked about the other. As when teaching Cumbia, I had more to gain by looking at the good side of things.
During his amazing opening keynote, Niko Matsakis said that he was skeptical and pessimistic by nature, and that he was, at first, worried about whether people using Rust also liked it. At that point I looked at The Boss because I knew he would be nodding at me, the company’s “designated pessimist”, the one that always assumes the worst. Niko then moved on to show that a lot of people were, in fact, loving Rust and that this was in part for its features but largely because of the sense of craftsmanship that they enabled and the community that grew around it.
I don’t hold an especially romantic view of Open-Source. At the end of the day, it’s just another way of doing business, like most professional activities are. Capitalism has this way of ingesting everything, even what antagonizes it, and turn it into business. I don’t think Open-Source, nor technology for that matter, can change the world, but I do feel proud about being part of a discipline where there’s still room for passion and craftsmanship; a discipline that proves that fellowship and collaboration can be the best way of making progress.
Holiday Ping design notes
After joining LambdaClass, I’ve been working on an Open-Source application using Erlang and ClojureScript. I Published the design notes in two articles at Not A Monad Tutorial:
- Holiday Ping: how we implemented our first open source app with Erlang and Clojurescript
- One does not simply build a user interface: our ClojureScript/re-frame app
Interview for This is not a Monad tutorial
unbalancedparen interviewed me for his blog This is not a Monad tutorial. I elaborated on some of the topics I usually write about in this blog, like Python, Clojure and Open Source programming.
This is unfortunate and we’re stuck with it forever
I. Some weeks ago, at NodeConf Argentina, Mathias Bynens gave a presentation about RegExp and Unicode in JavaScript. At some point he showed a series of examples that yielded counter-intuitive results and said: “This is unfortunate and we’re stuck with it forever”. The phrase immediately resounded in my head, because to me it was a perfect definition of JavaScript, or at least the current state of JavaScript.
II. Douglas Crockford published JavaScript: The Good Parts about eight years ago. It’s a masterpiece to me, with a lot of takeaways: JavaScript is loaded with crap (the bad and awful parts); there’s a great functional language somewhere in there, striving to get out; sometimes, a lot of the times, less is more. The book itself is the perfect example: 100 pages long, mostly filled with snippets and examples, and still it had a clearer purpose and communicated it more effectively than most computer books. We can (and we should) make a better language out of JavaScript by subsetting it.
III. JavaScript and its ecosystem have been evolving constantly over the last few years; I imagine it mutated faster than any other programming language has done before. And a lot of the changes are genuinely good additions, that make our lives easier and more pleasant. But is JavaScript as a whole getting any better?
IV. Unlike any other language, JavaScript runs in browsers. And we can’t control the runtime of the browsers. And we want older browsers to support our new code, and new browsers to support our old code. We can’t break backwards compatibility. We can add (some) stuff to the language but we can’t take stuff out. All the bad and awful parts are still there. JavaScript is like a train wreck with a nose job.
V. I always wonder how is it like to learn JavaScript in 2016, for new programmers and for programmers coming from other languages. Do you tell them about var? Or just stick to let and const? And which one of those is preferred? And why the preferred one isn’t just the default? Why do we always have to prepend some operator to define a variable? Yes, we can instruct a linter to forbid this or that keyword (especially this!) but it should be the compiler/interpreter doing it. And we can’t make the interpreter assume a const declaration by default.
VI. Is there really no way to break backwards compatibility? Can’t we just stick a flag in there somewhere? <script language="javascript-good">? 'use non-crappy'? I don’t mind adding the 'use strict' on every file and I honestly forgot what it does. Can’t the browsers manage multiple versions of JavaScript? is it worth their save, especially now that this uneven language has crawled its way to the server and the desktop?
VII. I know there must be excellent reasons why we can’t break backwards compatibility of JavaScript or why it would be just too expensive to do so. But I can’t help my mind, my syntax-oriented-programmer-with-an-inclination-to-a-less-is-more-kind-of-thinking-type-of-mind, I can’t help it from imagining how would I go about subsetting the language. How would I design my JavaScript--. I can’t help myself from outlining a spec of that imaginary language in my head. I even came up with a name for it, which, unsurprisingly, has already been taken.
From Clojure to ClojureScript
Ever since I started working on the advenjure engine as a learning project for Clojure, I thought porting it to the browser would make a great excuse to get into ClojureScript as well. I finally took the time to do it a couple of weeks ago and now the engine is fully functional in both environments.
The process of going from zero to having some Clojure code running in the browser, source-maps included, was surprisingly easy. Making a fully functional Clojure project target the browser too was a bit more difficult, especially when dealing with JavaScript’s inherent asynchronous nature and setting up the ClojureScript compiler to bundle the project and its dependencies.
I document here the steps I took, useful reads, issues I found along the way and the sources where I got the solutions. For context, I’m using version 1.9.229 of ClojureScript.
Getting Started
Differences from Clojure was a good place to start getting an idea of what ClojureScript looks like coming from Clojure. After that, the Quick Start tutorial was all it took to get my code running in the browser, in Node.js and even in a ClojureScript REPL. With the boilerplate project from the tutorial I was able to start migrating bits of the advenjure codebase and running them in the browser console.
After testing most of the pure-logic parts of the project and being confortable that they could actually run in the browser, I had to deal with the files that were more or less dependant on Java interop. At this point I needed to review the Reader Conditionals documentation, here and here. The key takeaways where: Clojure specific logic goes in .clj files, ClojureScript in .cljs; shared logic goes in .cljc, using the conditional syntax in the parts that differ from one host to another:
(defn str->int [s]
#?(:clj (java.lang.Integer/parseInt s)
:cljs (js/parseInt s)))
Because of how macros work in ClojureScript, those needed to go either in .clj or .cljc files, and required using the :require-macros option:
(ns example.dialogs
#?(:clj (:require [advenjure.dialogs :refer [dialog]])
:cljs (:require-macros [advenjure.dialogs :refer [dialog]])))
With Reader Conditionals, println and js/prompt I had a fairly functional version of the example game running in the browser. The next step was to include jQuery terminal in the web page and use it as the interface for the game.
JavaScript interop and asyncrhonous code
Interop syntax is pretty simple, this article and the CloureScript Cheatsheet covered all I needed: the js/ namespace to access JavaScript globals and built-ins, js-obj for object literals, aget and aset to access them, dot prefix to invoke methods.
Things got a bit more complicated as I started integrating the jQuery terminal: my library was more or less a REPL, designed around the idea of waiting for user input and then processing it, but the terminal, as most JavaScript libraries, relied on callbacks and asynchronous processing. When the user enters a command, a processing function is called, which is detached from the game loop that holds the current game state and knows how to handle that command.
After googling around, core.async seemed like the most suitable tool to emulate the synchronicity that my codebase required. I’ve read about it earlier in the Brave Clojure book; this article was also helpful to get code samples.
My solution was to create an input channel where the jQuery terminal would write the commands:
(ns advenjure.ui.input (:require-macros [cljs.core.async.macros :refer [go]]) (:require [cljs.core.async :refer [<! >! chan]])) (def input-chan (chan)) (defn process-command "Callback passed to jQuery terminal upon initialization" [command] (go (>! input-chan command))) (defn get-input "Wait for input to be written in the input channel" [state] (go (<! input-chan)))
The main game loop that used to block waiting for user input now was a go-loop that “parked” until data came into the input channel:
(ns advenjure.game
(:require [advenjure.ui.input :refer [get-input exit]]
#?(:cljs [cljs.core.async :refer [<!]]))
#?(:cljs (:require-macros [cljs.core.async.macros :refer [go-loop]])))
#?(:clj
(defn run
[game-state finished?]
(loop [state game-state]
(let [input (get-input state)
new-state (process-input state input)]
(if-not (finished? new-state)
(recur new-state)
(exit))))))
#?(:cljs
(defn run
[game-state finished?]
(go-loop [state game-state]
(let [input (<! (get-input state))
new-state (process-input state input)]
(if-not (finished? new-state)
(recur new-state)
(exit))))))
This works well although it requires some amount of duplication between the Clojure and ClojureScript versions of the code. Advenjure dialog trees introduce more sophisticated ways of reading and processing user input, which threatened to leak the core.async logic into other portions of the codebase, thus causing more duplication. I managed to keep that to an acceptable minimum without loosing functionality, but there’s definitely room for improvement, perhaps coming up with some macro that abstracts host-specific differences behind a common syntax.
Reading, evaluating and persisting Clojure code
Some of the features of advenjure, such as dialogs and post/pre conditions, required storing quoted Clojure code in the game state, for later evaluation. I found that some built-ins I used to implement them, like read-string and eval, are not directly available in ClojureScript, but a bit of googling revealed how to bring them back.
Based on this article I came up with the following function to replace the native eval, using the tools in the cljs.js namespace:
(ns advenjure.eval
(:require [cljs.js]))
(defn eval [form] (cljs.js/eval
(cljs.js/empty-state)
form
{:eval cljs.js/js-eval
:source-map true
:context :expr}
:value))
As I learned later on, this snippet comes with one catch: when using Self-hosted ClojureScript (which is what cljs.js enables, evaluating ClojureScript code inside ClojureScript), you can’t use advanced compiler optimizations in your build.
While it’s not a built-in, read-string can be found in cljs.reader/read-string. In the Clojure version of my library, I was able to easily save and restore the game state to a file:
(defn save-game [game-state] (spit "saved.game" game-state)) (defn load-game [] (read-string (slurp "saved.game")))
I intended to do the same in ClojureScript, using the browser localStorage. This didn’t work right away, though, because the ClojureScript reader doesn’t know how to read records back from the storage. This script gave me the solution:
(require '[cljs.reader :refer [read-string register-tag-parser!]]
'[advenjure.items :refer [map->Item]]
'[advenjure.rooms :refer [map->Room]])
(defn save-game [game-state]
(aset js/localStorage "saved.game" (pr-str game-state)))
(register-tag-parser! "advenjure.items.Item" map->Item)
(register-tag-parser! "advenjure.rooms.Room" map->Room)
(defn load-game []
(read-string (aget js/localStorage "saved.game")))
Leiningen cljsbuild plugin
So far I was doing all the work inside the hello-world project from the Quick Start tutorial. Now that most of the engine was working in ClojureScript I had to integrate it back into the Clojure project and fix anything I broke to make sure it targeted both platforms. I’m using Leiningen so I looked into the lein-cljsbuild plugin. Since advenjure is a library intended to be used as a dependency in other projects, it didn’t matter much what configuration I put in there; the example project, though, ended up with the following configuration in its project.clj:
:plugins [[lein-cljsbuild "1.1.4"]]
:cljsbuild
{:builds
{:main {:source-paths ["src"]
:compiler {:output-to "main.js"
:main example.core
:optimizations :simple
:pretty-print false
:optimize-constants true
:static-fns true}}
:dev {:source-paths ["src"]
:compiler {:output-to "dev.js"
:main example.core
:optimizations :none
:source-map true
:pretty-print true}}}}
Then, running lein cljsbuild once would compile development and production versions of the game to be included in the HTML page. Note that, as mentioned, I couldn’t use :optimizations :advanced in the production build, because I was using the cljs.js namespace in my project.
Regular Expressions
Some of the features of advenjure relied on regular expressions. The Clojure related functions are backed by the host implementation of regexes, and JavaScript doesn’t support named capturing groups. To overcome this without changing the original code, I resorted to XRegExp, which fortunately respects the native JavaScript interfaces for regular expressions:
(def regexp #?(:clj re-pattern :cljs js/XRegExp)) (defn match-verb [verb-pattern input] (re-find (regexp verb-pattern) input))
Bundling foreign libs
Once everything worked as expected, I needed to figure out how to pack the library so it could be easily included in projects with minimum effort. Particularly, I needed a way to bundle the JavaScript dependencies (jQuery, jQuery terminal, etc.), so the users wouldn’t need to include them manually in their HTML. This topic can get a bit complex in ClojureScript, especially when dealing with advanced optimizations (which I learned along the way I wasn’t going to use). This and this are good references.
The CLJSJS project is an initiative that allows to easily require JavaScript libraries like regular Clojure dependencies. The problem is that the amount of supported libraries is limited, and contributing one of your own is not a trivial process (specifically, it seems to require Boot, and since I was already set up with Leiningen it didn’t look like an option at the moment).
I had to fallback to using the foreign-libs compiler option. For some reason, I couldn’t figure out how to make that work from the cljsbuild settings in my project.clj, so after reviewing this wiki entry I decided to include a deps.cljs file in the root of my source directory:
{:foreign-libs
[{:file "jquery/jquery-3.1.1.js"
:file-min "jquery/jquery-3.1.1.min.js"
:provides ["jquery"]}
{:file "jquery.terminal/jquery.terminal-0.11.10.js"
:file-min "jquery.terminal/jquery.terminal-0.11.10.min.js"
:requires ["jquery"]
:provides ["jquery.terminal"]}
{:file "jquery.terminal/jquery.mousewheel.js"
:file-min "jquery.terminal/jquery.mousewheel.min.js"
:requires ["jquery"]
:provides ["jquery.mousewheel"]}
{:file "xregexp/xregexp-all.js"
:file-min "xregexp/xregexp-all.min.js"
:provides ["xregexp"]}]
:externs ["jquery/externs.js" "jquery.terminal/externs.js" "xregexp/externs.js"]}
Some notes about it:
- I had to add the files and minified files to the resources folder of the library, to be used in the development and production builds respectively.
- I needed to define a
:providesname and require it in my codebase (no matter if the library exposes a global value that’s actually accesible throughjs/), in order for the compiler to include the library in the generated build. - The
:requiresis also important to establish dependencies between libraries; without it, the jQuery terminal code can be included before jQuery, which would cause a reference error when running in the browser. - The externs aren’t really necessary, since I wasn’t using advanced optimizations, but if I was I found this tool of great help in generating those files, especially for big libraries like jQuery. Smaller ones, like a jQuery plugin, I could create by hand; the CLJSJS packages can be a good reference in that case.
Real-world RPC with RabbitMQ and Node.JS
tl;dr: use the direct reply-to feature to implement RPC in RabbitMQ.
I’m currently working on a platform that relies heavily on RPC over RabbitMQ to move incoming requests through a chain of Node.JS worker processes. The high level setup for RPC is well described in RabbitMQ’s documentation; let’s steal their diagram:
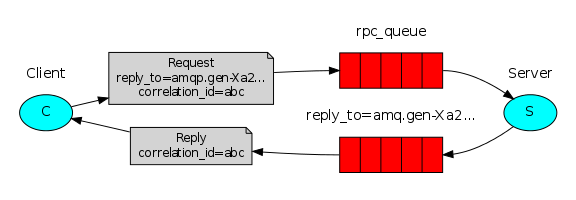
We grew our RPC client code based on the JavaScript tutorial, using the amqp.node module. The first —admittedly naive— implementation just created a new connection, channel and queue per request and killed the connection after getting a reply:
const sendRPCMessage = (settings, message, rpcQueue) =>
amqp.connect(settings.url, settings.socketOptions)
.then((conn) => conn.createChannel())
.then((channel) => channel.assertQueue('', settings.queueOptions)
.then((replyQueue) => new Promise((resolve, reject) => {
const correlationId = uuid.v4();
const msgProperties = {
correlationId,
replyTo: replyQueue.queue
};
function consumeAndReply (msg) {
if (!msg) return reject(Error.create('consumer cancelled by rabbitmq'));
if (msg.properties.correlationId === correlationId) {
resolve(msg.content);
}
}
channel.consume(replyQueue.queue, consumeAndReply, {noAck: true})
.then(() => channel.sendToQueue(rpcQueue, new Buffer(message), msgProperties));
})));
That got us a long way during development but obviously failed to perform under non-trivial loads. What was more shocking is that it got dramatically worse when running it on a RabbitMQ cluster.
So we needed to refactor our client code. The problem is that most examples show how to send one-off RPC messages, but aren’t that clear on how the approach would be used at scale on a long-lived process. We obviously needed to reuse the connection but how about the channel? Should I create a new callback queue per incoming request or a single one per client?
Using a single reply-to queue per client
Based on the tutorial, I understood that the sensible approach was to reuse the queue from which the client consumed the RPC replies:
In the method presented above we suggest creating a callback queue for every RPC request. That’s pretty inefficient, but fortunately there is a better way – let’s create a single callback queue per client. That raises a new issue, having received a response in that queue it’s not clear to which request the response belongs. That’s when the correlation_id property is used.
We were already checking the correlationId, and just needed to create the reply-to queue in advance:
const createClient = (settings) =>
amqp.connect(settings.url, settings.socketOptions)
.then((conn) => conn.createChannel())
.then((channel) => channel.assertQueue('', settings.queueOptions)
.then((replyQueue) => {
channel.replyQueue = replyQueue.queue;
return channel;
}));
I thought that would be enough to make sure the right consumer got the right message, but in practice I found that each message was always delivered to the first consumer. Therefore, I needed to cancel the consumer after the reply was processed:
const sendRPCMessage = (channel, message, rpcQueue) =>
new Promise((resolve, reject) => {
const correlationId = uuid.v4();
const msgProperties = {
correlationId,
replyTo: channel.replyQueue
};
function consumeAndReply (msg) {
if (!msg) return reject(Error.create('consumer cancelled by rabbitmq'));
if (msg.properties.correlationId === correlationId) {
channel.cancel(correlationId)
.then(() => resolve(resolve(msg.content)));
}
}
channel.consume(channel.replyQueue, consumeAndReply, {
noAck: true,
// use the correlationId as a consumerTag to cancel the consumer later
consumerTag: correlationId
})
.then(() => channel.sendToQueue(rpcQueue, new Buffer(message), msgProperties));
});
Enough? Only if the client processed one request at a time. As soon as I added some concurrency I saw that some of the messages were not handled at all. They were picked up by the wrong consumer, which ignored them because of the correlationId check, so they were lost. I needed to do something about unexpected message handling.
Requeuing unexpected messages
I tried using nack when a consumer received a reply to a message with an unexpected correlationId:
function consumeAndReply (msg) {
if (!msg) return reject(Error.create('consumer cancelled by rabbitmq'));
if (msg.properties.correlationId === correlationId) {
channel.ack(msg);
channel.cancel(correlationId)
.then(() => resolve(resolve(msg.content)));
} else {
channel.nack(msg);
}
}
Now the messages seemed to be handled, eventually. Only they weren’t: when I increased the load I saw message loss again. Further inspection revealed that the consumers were entering a weird infinite loop:
Consumer A gets message B; message B requeued Consumer B gets message C; Message C requeued Consumer C gets message A; Message A requeued
Repeated ad-infinitum. The same behaviour was reproduced using every possible combination of nack, reject and sendToQueue to send back the message.
Googling the issue, I read about the possibility of using Dead letter exchanges to handle those cases. But having to manually requeue unexpected messages felt weird enough; introducing a new exchange and queue sounded like a lot of effort to handle what should be a pretty standard use case for RPC. Better to take a step back.
Using a new reply-to queue per request
So I went back to a reply-to queue per request. This was marginally better than our initial approach since now at least we were recycling the connection and the channel. What’s more, that appeared to be the standard way to do RPC in RabbitMQ according to the few spots where I found non-tutorial implementation details, so, as Paul Graham would say, we wouldn’t get in trouble for using it.
And it worked well for us as long as we run a single RabbitMQ instance. When we moved to a RabbitMQ cluster the performance was pretty much the same as when we were creating connections like there was no tomorrow.
Using direct reply-to
We were seriously considering dropping the RabbitMQ cluster altogether (which meant turning our broker into a single point of failure), when I came across the link to the direct reply-to documentation. The first interesting thing there was that it confirmed why we were seeing such bad performance when running a RabbitMQ cluster:
The client can declare a single-use queue for each request-response pair. But this is inefficient; even a transient unmirrored queue can be expensive to create and then delete (compared with the cost of sending a message). This is especially true in a cluster as all cluster nodes need to agree that the queue has been created, even if it is unmirrored.
Direct reply-to uses a pseudo-queue instead, avoiding the queue declaration cost. And fortunately it was fairly straightforward to implement:
const createClient = (settings) => amqp.connect(settings.url, settings.socketOptions)
const sendRPCMessage = (client, message, rpcQueue) => conn.createChannel()
.then((channel) => new Promise((resolve, reject) => {
const replyToQueue = 'amq.rabbitmq.reply-to';
const timeout = setTimeout(() => channel.close(), 10000);
const correlationId = uuid.v4();
const msgProperties = {
correlationId,
replyTo: replyToQueue
};
function consumeAndReply (msg) {
if (!msg) return reject(Error.create('consumer cancelled by rabbitmq'));
if (msg.properties.correlationId === correlationId) {
resolve(msg.content);
clearTimeout(timeout);
channel.close();
}
}
channel.consume(replyToQueue, consumeAndReply, {noAck: true})
.then(() => channel.sendToQueue(rpcQueue, new Buffer(content), msgProperties))
});
This worked just as we expected, even in the cluster. As the code shows, though, we were still creating a new channel per request and we needed to handle its closing, even when the response never came. Trying to use a single channel resulted in a “reply consumer already set” error, because the queue was always the same.
Creating so many channels didn’t feel right, so I filed an issue asking for advice in the amqp.node repo. The creator confirmed that that was indeed an anti-pattern and suggested not only using a single channel but registering a single consumer (i.e. a single callback function to handle all RPC responses). This meant introducing some structure to be able to route responses back to the promise that was expecting it. Using an EventEmitter turned out to be an elegant way to accomplish it:
const REPLY_QUEUE = 'amq.rabbitmq.reply-to';
const createClient = (settings) => amqp.connect(settings.url, settings.socketOptions)
.then((conn) => conn.createChannel())
.then((channel) => {
// create an event emitter where rpc responses will be published by correlationId
channel.responseEmitter = new EventEmitter();
channel.responseEmitter.setMaxListeners(0);
channel.consume(REPLY_QUEUE,
(msg) => channel.responseEmitter.emit(msg.properties.correlationId, msg.content),
{noAck: true});
return channel;
});
const sendRPCMessage = (channel, message, rpcQueue) => new Promise((resolve) => {
const correlationId = uuid.v4();
// listen for the content emitted on the correlationId event
channel.responseEmitter.once(correlationId, resolve);
channel.sendToQueue(rpcQueue, new Buffer(message), { correlationId, replyTo: REPLY_QUEUE })
});
Clojure: the good, the bad and the ugly
Four years ago I wrote about my first (and last) experience with Common Lisp. I had high expectations and was disappointed; I ended up thinking maybe I should give Scheme or Clojure a try. It took a while, but I finally did it last month: learn Clojure. And it looks like a keeper.
Clojure has all the goodness of Lisp and functional programming, and it feels like a modern language: it addresses most of things that annoyed me about Common Lisp.
I’ve followed the great Clojure for the brave and true book by Daniel Higginbotham and then I’ve tackled a small project to train my skills. Here are my notes.
The good
- A consistent syntax, operation names and polymorphic functions. No weird illegible names, no type specific versions of the same function (I’m looking at you Common Lisp).
- Functional! Immutable! Expressive!
- I don’t miss objects. Structuring programs in small functions; isolated, never changing data; those things just feel right. And I’m not even waving the old “shared state is bad for concurrency” flag; I don’t care —just now— about concurrency. This stuff makes programs simpler to reason about and test, and more fun to write.
- There’s more: Clojure is so expressive and gives you enough options (I’m thinking loop, doseq, destructuring, etc.) that you don’t necessarily need to incur in “head/tail” recursive processing as much as I found in other functional languages, so the leap is not so rough.
- Did I say I don’t care about concurrency? I don’t. Mostly. Not at the language level, anyway. Clojure has a lot of cool tools for concurrency (future, delay, promise, pmap, core.async). Too much options, maybe, but I don’t mind about that either. I can just RTFM whenever I do have the need to do things concurrently. And, yes, immutability and pure functions make it simpler.
- A strong philosophy behind the language, that seems to drive its design. Python has this too and to me it’s its biggest selling point. Languages like C++ and increasingly JavaScript, on the other hand, feel like magic bags where features are added carelessly without consideration of the results. Java does have a strong philosophy: programmers are mostly idiots.
- Runs on the JVM. Seriously? I personally couldn’t care less about that but JVM languages seem to attract a lot of attention. There are tons of Java devs for sure and some of them seem to have a symbiotic relationship with the JVM: it’s like they aren’t cheating on Java if they keep the deal inside the VM. Why would people learn Groovy instead of Ruby or Python, god only knows, but because of the “Runs in Java” part there’s a better chance of finding a Clojure Job than one using Haskell, Scheme or most other functional languages around. That alone is enough reason for me to stick with Clojure instead of keep trying Lisp dialects, even if some other one may fit my taste better.
- Haven’t tried it yet, but the mere existence of ClojureScript is good news to me, specially considering how annoyed I am with the direction the JavaScript syntax and ecosystem is taking lately. This talk totally sold it to me.
- Said it before and say it again: forget about parenthesis. People seem to worry a lot about them beforehand, but as with Python whitespace indentation, once you’ve used it for five minutes it just goes away. Specially if you use the darn awesome Parinfer.
- Which brings me to: you don’t need Emacs for Lisp programming. Yes, I hear you, once I master Emacs I’ll be a more powerful programmer. But I’m trying to learn a weird language here, don’t make me also learn a weird, counter-intuitive editor at the same time. That would just increase the chances of me dropping the effort altogether. There are decent ports of Paredit for Sublime and Atom, which is good enough. But with Parinfer you just learn one command and forget about it, it just works.
- REPL driven development. Because of pure functions it’s easy to write a piece of code and test it right away in the REPL. Together with unit tests it pretty much removes the need for debugging.
- Leiningen looks good, it covers the small needs I had starting out and didn’t get in the way. Clojurians say it does a lot more than that, so great. Much better than the 17 tools you need to set up to have a Node.js project running these days.
The bad
- Namespace syntax is complicated, there are too many operations and keywords to do it (require, refer, use, alias, import and ns —which can do all of the others with a slightly different notation). It’s flexible but boilerplatish, even when sticking to ns:
(ns advenjure.game
(:require [advenjure.rooms :as rooms]
[advenjure.utils :as utils]
[advenjure.verb-map :refer [find-verb verb-map]]))
- And while there’s no hard rule to keep a one to one relation between files and namespaces, there’s a strong convention to do it, so having to declare the package name in every file seems totally redundant (and Java-ish, let’s be honest).
- contains? Works in a counter-intuitive way for vectors.
That’s all I got.
And the ugly
Ok, there wasn’t much bad stuff, but there is some maybe not so good or arguably not good things I can think of.
- The built in operator set doesn’t follow the Unix and Python philosophy of small core and a lot of libraries that I like so much: the functions are way too many to easily remember, and they aren’t entirely orthogonal (some of them do the same thing in slightly different ways). Then again, the Clojure Cheatsheet, the REPL and doc are more than enough to cope with that.
- Polymorphism is great: sequence and collection functions work as expected in all data structures. The downside is that to do so the results are always coerced to seqs, which may be unexpected, specially for hash maps. In practice, though, I found myself just chaining those functions and rarely caring about the resulting type.
- Macros are powerful and awesome but the quoting syntax can get very tricky. I definitely need more experience to learn to reason about macro code, but the syntax will remain ugly. I guess that’s the cost you pay for being able to fiddle with how the language processes the code. In the end (much like Python metaclasses), macros are a great tool to keep in the box, but to use sparingly. So far every time I thought about implementing one I got away fine by using closures instead.
- Java does sneak in quite a bit and that’s a turn off. (spoiler alert: I don’t like Java). OK, Java interop is simple and powerful, probably the most straightforward language interfacing I’ve seen (boy was SWIG a nightmare). That being said, Java code inside Clojure looks like, well, Java code inside Clojure: it reeks. This wouldn’t be so much of a problem if needed only to interact with some third party Java libraries, but in practice I’ve found that there’s basic stuff lacking in the Clojure standard library and it’s either add a dependency or use Java interop. I saw this while solving an exercise from the Brave Clojure book: it asked to list the first results of a google search. The request should be a one liner using the built in slurp function but, wait, you need to set the User-Agent header to request google, so you end up with:
(with-open [inputstream (-> (java.net.URL. url)
.openConnection
(doto (.setRequestProperty "User-Agent"
"Mozilla/5.0 ..."))
.getContent)]
The end
Even though it’s not my ideal language and it may be less ideal to me than Python was, it looks like I’ll start to look for excuses to use Clojure as much as possible and it’ll be a while before I jump to study another new language.
Panda vs Zombies: my new Android video game

Over most of last year I’ve been working along a couple of college friends on an action game for Android and it’s finally out. It’s done using cocos2d-x in C++, which is by no means a language I like, so hopefully I’ll get to write here about the experience I had building it.
In the meantime, here’s the link to install it from the google play store and the trailer of the game, for those who are interested in checking it out.
Better authentication for socket.io (no query strings!)
Introduction
This post describes an authentication method for socket.io that sends the credentials in a message after connection, rather than including them in the query string as usually done. Note that the implementation is already packed in the socketio-auth module, so you should use that instead of the code below.
The reason to use this approach is that putting credentials in a query string is generally a bad security practice (see this, this and this), and though some of the frequent risks may not apply to the socket.io connection request, it should be avoided as there’s no general convention in treating urls as sensitive information. Ideally such data should travel on a header, but that doesn’t seem to be an option for socket.io, as not all of the transports it supports (WebSocket being one) allow sending headers.
Needless to say, all of this should be done over HTTPS, otherwise no security level is to be expected.
Implementation
In order to authenticate socket.io connections, most tutorials suggest to do something like:
io.set('authorization', function (handshakeData, callback) {
var token = handshakeData.query.token;
//will call callback(null, true) if authorized
checkAuthToken(token, callback);
});
Or, with the middleware syntax introduced in socket.io 1.0:
io.use(function(socket, next) {
var token = socket.request.query.token;
checkAuthToken(token, function(err, authorized){
if (err || !authorized) {
next(new Error("not authorized"));
}
next();
});
});
Then the client would connect to the server passing its credentials, which can be an authorization token, user and password or whatever value that can be used for authentication:
socket = io.connect('http://localhost', {
query: "token=" + myAuthToken
});
The problem with this approach is that it credentials information in a query string, that is as part of an url. As mentioned, this is not a good idea since urls can be logged and cached and are not generally treated as sensitive information.
My workaround for this was to allow the clients to establish a connection, but force them to send an authentication message before they can actually start emitting and receiving data. Upon connection, the server marks the socket as not authenticated and adds a listener to an ‘authenticate’ event:
var io = require('socket.io').listen(app);
io.on('connection', function(socket){
socket.auth = false;
socket.on('authenticate', function(data){
//check the auth data sent by the client
checkAuthToken(data.token, function(err, success){
if (!err && success){
console.log("Authenticated socket ", socket.id);
socket.auth = true;
}
});
});
setTimeout(function(){
//If the socket didn't authenticate, disconnect it
if (!socket.auth) {
console.log("Disconnecting socket ", socket.id);
socket.disconnect('unauthorized');
}
}, 1000);
}
A timeout is added to disconnect the client if it didn’t authenticate after a second. The client will emit it’s auth data to the ‘authenticate’ event right after connection:
var socket = io.connect('http://localhost');
socket.on('connect', function(){
socket.emit('authenticate', {token: myAuthToken});
});
An extra step is required to prevent the client from receiving broadcast messages during that window where it’s connected but not authenticated. Doing that required fiddling a bit with the socket.io namespaces code; the socket is removed from the object that tracks the connections to the namespace:
var _ = require('underscore');
var io = require('socket.io').listen(app);
_.each(io.nsps, function(nsp){
nsp.on('connect', function(socket){
if (!socket.auth) {
console.log("removing socket from", nsp.name)
delete nsp.connected[socket.id];
}
});
});
Then, when the client does authenticate, we set it back as connected to those namespaces where it was connected:
socket.on('authenticate', function(data){
//check the auth data sent by the client
checkAuthToken(data.token, function(err, success){
if (!err && success){
console.log("Authenticated socket ", socket.id);
socket.auth = true;
_.each(io.nsps, function(nsp) {
if(_.findWhere(nsp.sockets, {id: socket.id})) {
console.log("restoring socket to", nsp.name);
nsp.connected[socket.id] = socket;
}
});
}
});
});
